강의의 절반을 차지하는 기본 개념들은 단독 문제로 거의 출제되지 않는다는 말이 있기에 2부에 해당하는 Serverless 이전의 기본 개념들(EC2, S3, DB, Route53 등)은 거의 개념만 볼 계획이고, DynamoDB, Lambda, CI/CD 중심으로 공부를 진행하려고 한다.
덤프는 examtopics 를 추천하길래 그 위주로 문제를 풀어볼 생각이고, 실제로 discussion을 통해 정답에 대한 사람들의 의견도 볼 수 있어서 정확하게 파악하기 좋을 것 같다.
오랫만에 일상의 기록 23년에는 한 번도 기록을 하지 않았더라구.. 물론 23년에는 승토리와 처음으로 해외 여행도 다녀오고 연휴도 있었고 이직을 하기 때문에 회사일에 집중하기도 했다. 그래도 너무 오랜만에 MacBook Pro를 켜면서 켜져 있는 VScode 창을 보면서 끝내지 못한 포스팅도 있었고, 기록이 22년 12월을 마지막으로 멈춰 있는 상태를 발견하고나니 반성하자 나 자신..
오늘은 승토리와 함께 아침 일찍부터 낙성대역 근처 카페에 자리잡고 각자 해야 할 일을 하고서, 저녁에는 이사가야 할 집 구경도 하고 가구의 치수도 재는 등 하려고 나왔다. 물론 내 생각보다는 너무 늦게 나온편이긴 하지만 이 정도면 선방했지!
5월 19일에 이사도 가고 새로운 직장에 조금씩 익숙해지면 다시 본격적으로 꾸준히 업데이트하며 공부할 계획을 다시 세워보겠다! 서버 개설 및 유지, 관리와 같은 부분에서 많이 부족하다는 것을 느끼고 있고, 확실히 그동안 해왔던 임베디드와는 전혀 다른 성격을 지나고 있기 때문에 서버 모니터링 & VOC와 같은 내용들을 따라가는게 어렵긴 하다. 그와 관련해서 내 NAS 서버를 관리하면서 그런 부족한 부분을 채워가보면 어떨까 지금은 생각하고 있다.
우선은 이사에 집중하고 워크스페이스 관리를 좀 더 신경써서 주기적으로 내 스스로의 가치를 올릴 수 있도록 해보겠다.
그리고 요새는 부업과 관련된 내용을 나름대로 정리하고 있다. 세상에는 내가 모르던 분야에서 다양한 부업으로 제 2의 수익을 내는 방법이 많은것을 알고서 깜짝 놀랐고, 그런 방법을 습득하고 소소하게라도 제 2의 수입을 안정적으로 만들 수 있는 노력을 할 예정이다.
또한 승토리와 6월에 결혼을 준비하는 단계에 도입하기로 했다. 이것은 엄청나게 의미 있는 것이며, 인생에서 전환기가 될 수 있다고 생각한다. 지금 이사가는 집에서 같이 시작하기에는 내가 생각했던 부분보다는 소소할 수 있겠지만, 차근차근 준비해보려고 한다. 💪
전송 제어 프로토콜의 약자로, 인터넷 프로토콜 스위프트(IP)의 핵심 프로토콜 중 하나로, IP와 함께 TCP/IP라는 명칭으로 불린다.
TCP/IP 를 사용하겠다는 것은 IP 주소 체계를 따르고 IP Routing을 이용해 목적지에 도달하며 TCP 의 특성을 활용해 송신자와 수신자의 논리적 연결을 생성하고 신뢰성을 유지할 수 있도록 하겠다는 의미이다. 즉, TCP/IP를 말한다는 것은 송신자가 수신자에게 IP 주소를 사용하여 데이터를 전달하고 그 데이터가 제대로 도달했는지, 너무 빠르진 않았는지, 받았다는 응답이 오는지에 대한 이야기를 하는 것이다.
Transport Layer(4 Layer)
송신자와 수신자의 논리적 연결을 담당하는 부분으로, 신뢰성 있는 연결을 유지할 수 있도록 도와줍니다. 즉 Endpoint(사용자) 간의 연결을 생성하고 데이터를 얼마나 보냈는지, 얼마나 받았는지, 제대로 받았는지 등을 확인합니다. TCP와 UDP가 대표적입니다.
Network Layer(3 Layer)
IP(Internet Protocol)이 활용되는 부분으로, 한 Endpoint가 다른 Endpoint로 가고자 하는 경우 경로와 목적지를 찾아줍니다. 이를 Routing이라고 하며 대역이 다른 IP들이 목적지를 향해 제대로 찾아갈 수 있도록 돕는 역할을 합니다,
출처 : OSI 7 Layer 쉽게 이해하기 [네트워크 엔지니어 환영의 AWS 기술블로그]
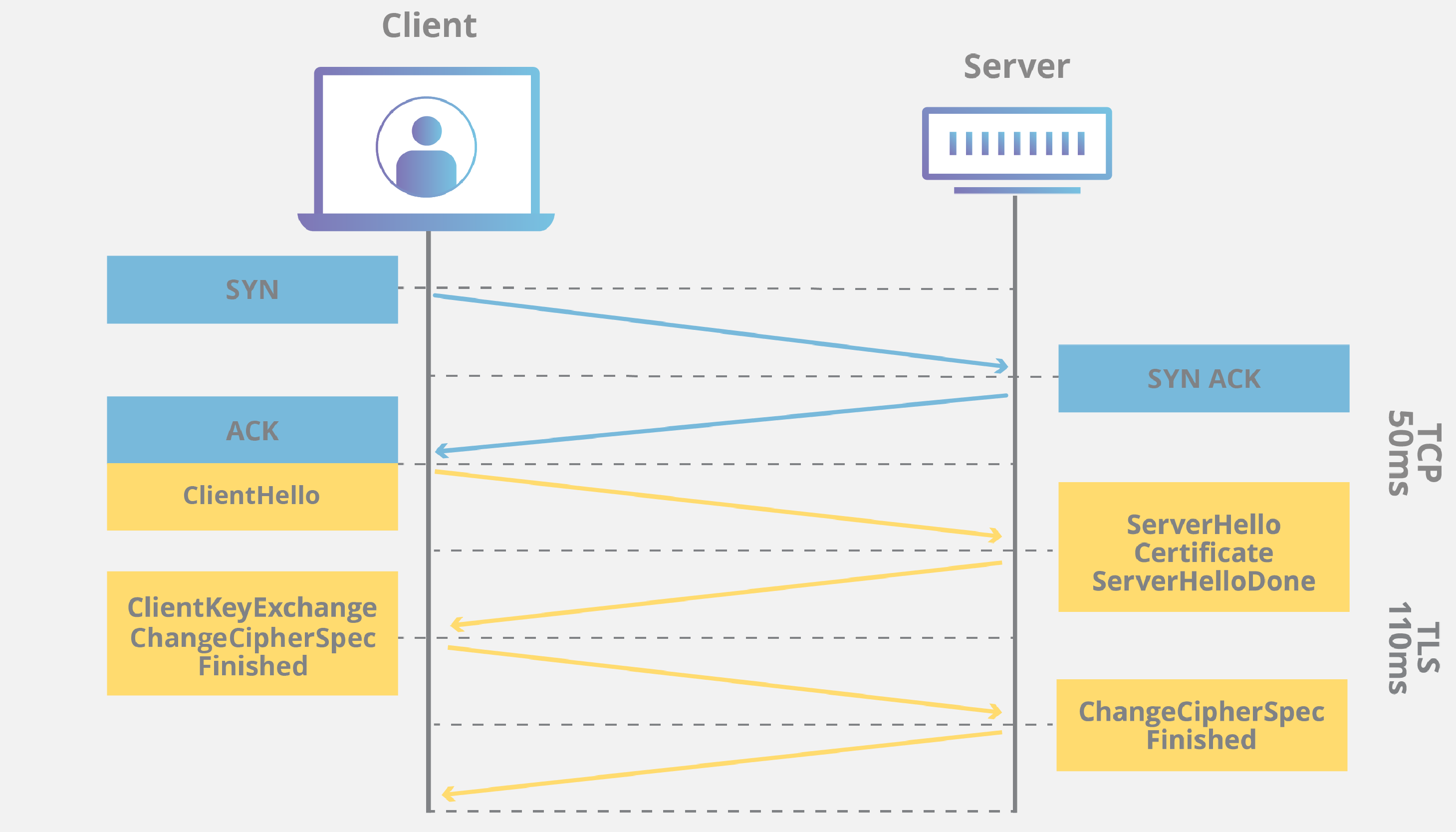
인터넷에서 무언가를 다운로드할 때 중간에 끊기거나 빠지는 부분 없이 완벽하게 받을 수 있는 이유도 TCP의 이러한 특성 덕분이다. 그렇게 때문에 위에서 언급한 것처럼 HTTP, HTTPS, FTP, SMTP 등과 같이 데이터를 안정적으로 모두 보내는 것을 중요시하는 프로토콜들의 기반이 된다. TCP를 기반으로 하는 프로토콜들은 TCP의 3-way handshake를 거친 후, 각자 프로토콜(Layer 7)에 기반한 교환 과정을 거친다는 의미이다.
위 이미지는 TCP 기반의 프로토콜인 HTTPS의 SSL handshake를 도식화한 것이다. TCP는 4 Layer이고 HTTPS는 7 Layer 이다.
파란색 부분은 TCP의 3-way handshake이고, 노란색 부분은 HTTPS의 SSL handshake이다. HTTPS는 TCP 기반이기 때문에 SSL handshake에 앞서 3-way handshake를 하는 것을 볼 수 있다.
TCP 개요
TCP는 OSI 7 Layer 중에 4 계층에 해당한다. IP가 그저 목적지를 제대로 찾아가는 것에 중점을 둔다면, TCP는 통신하고자 하는 양쪽 단말(Endpoint)이 통신할 준비가 되었는지, 데이터가 제대로 전송되었는지, 데이터가 가는 도중 변질되지는 않았는지, 수신자가 얼마나 받았고 빠진 부분은 없었는 등을 점검한다. 이런 정보는 TCP Header에 담겨 있으며 SYN, ACK, FIN, RST, Source Port, Destination Port, Sequence Number, Window Size, Checksum 등과 같은 신뢰성 보장과 흐름 제어, 혼잡 제어에 관여할 수 있는 요소들을 포함하고 있다. 또한 IP Header와 TCP Header를 제외한 TCP가 실을 수 있는 데이터의 크기를 세그먼트(Segment)라고 부른다.
`TCP Header의 구조(출처: Wikipedia)`
TCP는 IP의 정보들뿐만 아니라 Port를 이용하여 연결한다. 한 쪽 단말(Endpoint)에 도착한 데이터가 어느 입구(Port)로 들어가야 하는지 알아야 연결을 시도할 수 있기 때문이다.
프로세스 번호 : 모든 프로세스에는 프로세스 식별자를 저장하는 프로세스 ID 또는 PID라는 고유한 ID가 할당
프로그램 카운터 : 프로세스를 위해 실행될 다음 명령어의 주소를 포함하는 카운터를 저장
레지스터 : 누산기, 베이스, 레지스터 및 범용레지스터를 포함하는 CPU 레지스터에 있는 정보
메모리 제한 : 운영체제에서 사용하는 메모리 관리 시스템에 대한 정보
페이지 테이블 : 페이징 프로세스의 메모리 주소를 관리할 때 프로세스의 페이지 정보를 저장하고 있는 테이블
세그먼트 테이블 : 프로세스를 논리적으로 잘라 메모리에 배치하는 방식을 세그멘테이션이라고 한다. 세그먼트 테이블은 이 세그먼트들의 실제 물리적 메모리 주소의 정보를 담고 있다.
열린 파일 목록 : 프로세스를 위해 열린 파일 목록
Accountin 정보 : Process를 실행한 유저 정보
I/O 상태 정보 : Process에 할당된 물리적 장치 및 프로세스가 읽고 있는 파일에 관한 정보
Process 생성
프로세스 생성은 부모 프로세스가 연산을 통해 자식 프로세스를 만들어낸다. 생성된 자식 프로세스 또한 새로운 자식 프로세스를 만들 수 있으며, 이를 구별하기 위해 모든 프로세스는 각자 고유의 PID를 가지고 있다. 이렇게 생성된 프로세스 간의 관계는 하나의 큰 트리구조가 된다.
생성된 자식 프로세스는 각자 고유의 PID, 메모리, CPU 등 새 PCB가 할당되며 고유의 자원을 획득하게 된다. 이로 인하여 부모 프로세스의 자원 접근에 제한이 생기며 특수한 방법을 통해 공유할 수 있게 된다.
프로세스를 생성한 후 부모 프로세스는 다음과 같이 2가지 행동을 할 수 있다.
자식 프로세스가 끝날 때까지 기다린다 ( -> waiting queue ) 자식 프로세스와 함께 동작 (멀티 프로세싱 환경)
자식 프로세스는 다음 중 하나의 프로세스가 된다.
부모 프로세스와 동일한 새로운 프로세스 : 이 경우 부모 프로세스의 프로그램, 데이터가 완전 복사
새로운 프로그램 실행 : 새로운 프로그램을 메모리에 load 하고 이를 실행
fork()
Linux/UNIX 환경에서 새로운 프로세스를 만드는 시스템 콜 함수
생성된 자식 프로세스는 부모 프로세스의 데이터와 프로그램이 완전 복사가 되어 똑같은 프로그램을 수행하는 프로세스가 된다. 멀티 프로세싱을 통해 부모, 자식 프로세스는 함께 동작한다. fork() 함수는 부모 프로세스에서 자식의 PID를 반환하고, 자식 프로세스에서는 0을 반환하여 구분할 수 있도록 해준다.
exec()
Linux/UNIX 환경에서 프로세스를 새로운 프로그램을 실행하는 프로세스로 대체하는 시스템 콜 함수
fork()와 다르게 자식 자식 프로세스를 생성하는 것이 아닌 현재 프로세스의 프로그램 코드를 새로운 프로그램 코드로 바꿔준다. 이로 인하여 프로그램 코드, 메모리, 파일 등 프로세스 자원이 새로 바뀌게 된다. exec() 함수는 현재 프로세스가 완전히 새로운 프로그램을 실행하는 프로세스로 대체되므로 반환 값이 없다.
보통 동작하는 방식은 fork()를 통해 자식 프로세스를 생성하고 자식 프로세스에서 exec()를 통해 새로운 프로그램을 돌리게 된다. 이때 부로 프로세스가 자식 프로세스가 끝나기를 기다려야 한다면 wait() 시스템 콜 함수를 이용하여 기다릴 수 있다.
Multi Process
두개 이상, 다수의 프로세서(CPU)가 협력적으로 하나 이상의 작업(Task)을 동시에 처리하는 것이다. (병렬처리) 각 프로세스 간 메모리 구분이 필요하거나 독립된 주소 공간을 가져야 할 경우 사용한다.
장점
독립된 구조로 안전성이 높은 장점이 있다.
프로세스 중 하나에 문제가 생겨도 다른 프로세스에 영향을 주지 않아, 작업속도가 느려지는 손해정도는 생기지만 정지되거나 하는 문제는 발생하지 않는다.
여러개의 프로세스가 처리되어야 할 때 동일한 데이터를 사용하고, 이러한 데이터를 하나의 디스크에 두고 모든 프로세서(CPU)가 이를 공유하면 비용적으로 저렴하다.
문제점
독립된 메모리 영역이기 때문에 작업량이 많을수록( Context Switching이 자주 일어나서 주소 공간의 공유가 잦을 경우) 오버헤드가 발생하여 성능저하가 발생 할 수 있다.
Context Switching 과정에서 캐시 메모리 초기화 등 무거운 작업이 진행되고 시간이 소모되는 등 오버헤드가 발생한다.
Context Switching
CPU는 한번에 하나의 프로세스만 실행 가능하다. 때문에 CPU에서 여러 프로세스를 돌아가면서 작업을 처리하는 데 이 과정을 Context Switching라 한다. 구체적으로, 동작 중인 프로세스가 대기를 하면서 해당 프로세스의 상태(Context)를 보관하고, 대기하고 있던 다음 순서의 프로세스가 동작하면서 이전에 보관했던 프로세스의 상태를 복구하는 작업을 말한다.
Process간 통신 방식 (IPC : Inter Process Communication)
프로세스 간 통신이란 프로세스가 서로 데이터를 주고받는 방법, 경로 등을 의미한다. 커널의 디자인에 따라 마이크로 커널, 나노 커널 등 통신이 많이 일어나는 디자인의 경우 IPC 방식이 성능을 크게 좌지우지할 수 있다.
Shared memory
운영체제의 도움을 받아 일부 영역의 메모리를 여러 프로세스가 동시에 접근할 수 있도록 권한을 받는다. 프로세스는 공유 메모리를 읽고 쓰면서 프로세스 간 통신을 하게 된다. 같은 메모리를 사용하는 환경에서 작동하므로 메모리에 접근하여 값을 변경하면 그 즉시 변경된 값이 반영되어 다른 프로세스들이 접근 시 변경된 값을 얻을 수 있다. 처음 메모리에 여러 프로세스가 접근 권한을 부여하는 작업에서만 커널 작업이 필요하고 이후엔 커널 동작이 필요 없다.
동작 과정
공유 메모리를 사용할 프로세스들 중 하나의 프로세스가 자신이 부여받은 메모리 영역 중 일부분을 선택 다른 프로세스 들은 공유할 메모리의 주소를 받아 이를 자신의 메모리 영역에 붙인다. 운영체제가 해당 프로세스들 간의 메모리 접근 제한을 풀어준다. 이후 프로세스들은 공유 메모리를 통해 통신
운영체제는 더 이상 관여할 필요 없으며 프로세스가 종료 시 메모리를 반환하면 공유 메모리 또한 같이 반환하게 된다.
Message Passing
데이터가 하나의 메시지가 되어 프로세스 간 통신을 하게 된다. 충돌 위험이 없기 때문에 소량의 데이터 전송에 유리 명령만을 주고받는 분산 시스템, 마이크로/나노 커널 방식에 유리 공유 메모리 방식과 다르게 같은 환경에 있지 않아도 인터넷을 통해서 메시지를 주고받을 수 있다. (소켓) 생산자-소비자 모델의 공유 메모리 방식을 이용하면 동기화 작업이 필요 없지만 메시지 전달 방식은 동기화 작업이 필요한 경우가 많습니다. 비동기, 동기 방식에 따라 결정한다.
Send, Receive 2가지 명령에 의해 동작
Direct communication : send, receive 동작이 특정 프로세스를 지정하며 메시지를 직접 주고 받는다.
Indirect communication : 프로세스들 가운데 하나의 시스템, 네트워크 등을 두고 메시지를 중재하며 동작한다. 직접 전달 방식보다 더 유연하게 동작할 수 있으며 중재 시스템의 구현에 따라 보안성, 성능 등 다양한 처리가 가능해진다.
동기, 비동기
메시지 전달 방식은 동기화 작업이 필요한데, 동기방식과 비동기 방식이 있다.
동기(Blocking, Synchronous) 동기 Send : 메시지를 보내고 나면 받는 프로세스에게 메시지가 도착할 때까지 다른 작업을 할 수 없다. 동기 Receive : 메시지를 받기 전까지 해당 프로세스는 다른 작업을 하지 않고 멈춰 있어야 한다.
비동기(Nonblocking, Asynchronous) 비동기 Send : 메시지를 보내고 프로세스는 멈추지 않고 다음 작업을 진행한다. 비동기 Receive : 메시지를 받으면 해당 메시지가 유효한 내용인지 검사를 하고 처리
버퍼 형태
Unbounded buffer : 메모리 버퍼의 크기에 제한이 없으며 소비자 프로세스는 새 자원이 만들어질 때까지 기다려야 하며 생산자 프로세스는 항상 새로운 자원을 만들 수 있다. 이때 생산자 역할의 프로세스는 공유한 메모리 자원의 크기를 지정하여 이를 함께 소비자 프로세스에 알려주어야 한다.
Bounded buffer : 메모리 버퍼 크기에 제한이 있으며 소비자 프로세스는 버퍼가 빈 상황이면 새로운 자원이 채워질 때까지 기다리며 생산자 프로세스는 버퍼가 꽉 차 있으면 공간이 남을 때까지 기다려야 한다.
File 사용
텍스트 파일txt(혹은 다른 포멧의 파일)을 통해 데이터를 주고 받는 것도 IPC 기법 중 하나이다.
물론 이 방식은 문제가 많다. 이 방식은 실시간으로 직접 원하는 프로세스에 데이터 전달하는게 어렵기 때문이다. 디스크에서 데이터 파일을 읽고, 프로세스에 적재load되는 과정에서 컨텍스트 스위칭Context-switching, 인터럽트Interrupt 등 여러 일을 처리해야 하기 때문이다.
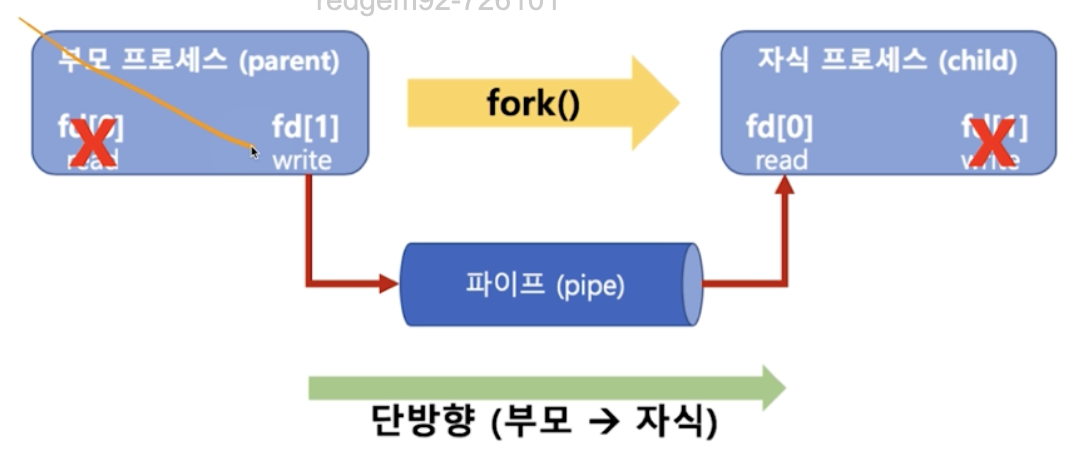
파이프(Pipe)
단방향 통신, 즉 부모 프로세스 → 자식 프로세스에게 일방적으로 통신하는 기법으로, fork()를 통해 자식 프로세스를 만들고 나서 부모의 데이터를 자식에게 보낸다.
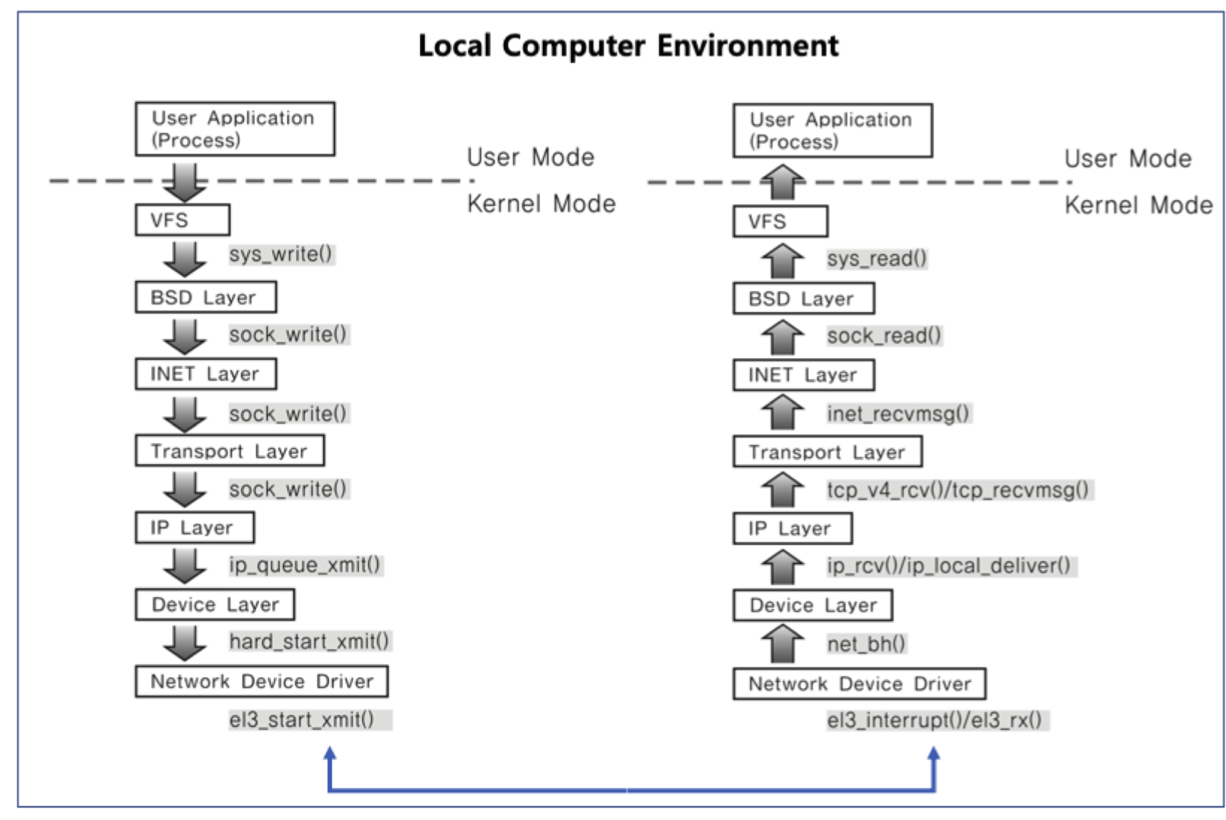
소켓(Socket)
많이 쓰이는 기법이자, 본래 목적이 IPC로 활용하기 위한 것은 아니지만, 충분히 활용이 가능하다.
본래 소켓은 네트워크 통신을 위한 기술이다. 기본적으로 클라이언트와 서버 등 두 개의 다른 컴퓨터 간의 네트워크 기반 통신을 위한 기술로, 네트워크 디바이스를 사용할 수 있는 시스템 콜이기도 하다. 소켓은 이렇게 클라이언트와 서버 뿐만 아니라, 하나의 컴퓨터 안에서 두 개의 프로세스 간의 통신 기법으로 활용하는 경우도 더러 있다.
소켓을 사용하면 로컬 컴퓨터간의 통신 시 이렇게 계층을 타고 내려가면서 송신을 하고, 아래 계층부터 위로 올라가서 대상 프로세스가 수신을 하는 방식을 취하게 된다.
Thread 란?
사실 프로세스가 단일의 실행 쓰레드를 실행하는 프로그램이다. 진짜로 일하는 것은 쓰레드라고 보면 된다.
Multi Thread
하나의 프로세스에 여러 스레드로 자원을 공유하며 작업을 나누어 수행하는 것이다.
장점
시스템 자원소모 감소 (자원의 효율성 증대)
프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어 자원을 효율적으로 관리할 수 있다.
시스템 처리율 향상 (처리비용 감소)
스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어든다.
스레드 사이 작업량이 작아 Context Switching이 빠르다. (캐시 메모리를 비울 필요가 없다.)
간단한 통신 방법으로 프로그램 응답시간 단축
스레드는 프로세스 내 스택영역을 제외한 메모리 영역을 공유하기에 통신 비용이 적다.
힙 영역을 공유하므로 데이터를 주고 받을 수 있다.
문제점
자원을 공유하기에 동기화 문제가 발생할 수 있다. (병목현상, 데드락 등)
주의 깊은 설계가 필요하고 디버깅이 어렵다. (불필요 부분까지 동기화하면, 대기시간으로 인해 성능저하 발생)
하나의 스레드에 문제가 생기면 전체 프로세스가 영향을 받는다.
단일 프로세스 시스템의 경우 효과를 기대하기 어렵다.
Process와 Thread의 차이
프로세스는 현재 실행되고 있는 프로그램으로 메모리에 올라와서 독립적인 메모리 공간을 가진다.
쓰레드는 프로세스 내에서 실행되는 흐름으로 프로세스 자원을 공유한다.
멀티 스레드 vs 멀티 프로세스
멀티 스레드는 멀티 프로세스보다 적은 메모리 공간을 차지하고 Context Switching이 빠른 장점이 있지만, 동기화 문제와 하나의 스레드 장애로 전체 스레드가 종료 될 위험을 갖고 있다.
멀티 프로세스는 하나의 프로세스가 죽더라도 다른 프로세스에 영향을 주지 않아 안정성이 높지만, 멀티 스레드보다 많은 메모리공간과 CPU 시간을 차지하는 단점이 있다.
두 방법은 동시에 여러 작업을 수행하는 점에서 동일하지만, 각각의 장단이 있으므로 적용하는 시스템에 따라 적합한 동작 방식을 선택하고 적용해야 한다.
왜 멀티 스레드로 나눠가며 할까?
운영체제가 시스템 자원을 효율적으로 관리하기 위해 스레드를 사용한다.
멀티 프로세스로 실행되는 작업을 멀티 스레드로 실행할 경우, 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
또한, 프로세스 간의 통신보다 스레드 간의 통신 비용이 적으므로 작업들 간 통신의 부담이 줄어든다. (처리비용 감소. 프로세스는 독립구조이기 때문)
그렇다면 무조건 멀티 스레드가 좋은가?
스레드를 활용하면 자원의 효율성이 증가하기도 하지만, 스레드 간의 자원 공유는 전역 변수를 이용하므로 동기화 문제가 발생 할 수 있으므로 프로그래머의 주의가 필요하다.
좀비 & 고아 프로세스
좀비 프로세스
자식 프로세스가 부모 프로세스보다 먼저 죽는 경우 부모 프로세스가 종료 상태를 회수하기 위해 커널이 자식 프로세스의 최소한의 정보(PID, 종료 상태 등, 리눅스의 경우 커널에서 사용하는 구조체)를 남겨 둔다. 부모 프로세스는 wait 함수를 호출하여 이 상태를 회수하면 남은 모든 정보가 제거되어 자식 프로세스는 완전히 소멸하게 된다.
위와 같은 진행상황에서 부모 프로세스가 wait 함수를 호출하지 않아 최소한의 정보가 메모리에 남아 있는 경우를 좀비 프로세스라고 한다. 좀비 프로세스는 최소한의 정보만을 가지고 있어 큰 성능 저하를 야기하지 않지만, 운영체제는 한정된 PID를 가지고 있으므로 좀비 프로세스가 PID를 차지하며 다른 프로세스 실행을 방해하게 된다. 따라서 부모 프로세스는 좀비 프로세스 생성을 방지하기 위해 wait 함수를 호출하여 상태를 회수하여야 한다.
커널 입장에서 좀비 프로세스는 성능 저하를 일으킨다고 볼 수 있다. 프로세스 스케줄링에 있어서 queue에 걸려있는 프로세스의 양이 증가하고 커널 구조체를 유지하기 위한 비용 또한 무시할 수 없다.
좀비 프로세스를 다음과 같은 방법으로 관리할 수 있다.
wait : 간단하게 부모 프로세스에서 wait 함수를 호출하여 좀비 프로세스를 없앨 수 있다.
signal, wait : wait 함수는 블록 모드로 동작하는 함수이므로 부모 프로세스는 wait함수를 호출한 즉시 동작을 멈추게 된다. 이를 방지하기 위해 시그널 도구를 활용하여 자식 프로세스가 종료될 경우 발생하는 SIGCHLD 시그널에 해당하는 핸들러를 만들고 해당 핸들러에서 wait 함수를 호출하면 된다.
고아 프로세스(Orphan)
부모 프로세스가 자식 프로세스보다 먼저 종료되는 경우 부모 프로세스가 없는 자식 프로세스를 말한다. 운영체제는 이러한 고아 프로세스를 허용하지 않으며 부모 프로세스가 먼저 종료되면 자식 프로세스의 새로운 부모 프로세스로 init(PID = 1)가 설정된다.
init 프로세스는 자식 프로세스가 종료될 때까지 기다린 후 wait 함수를 호출하여 고아 프로세스의 종료 상태를 회수하여 좀비 프로세스가 되는 것을 방지한다. 고아 프로세스는 프로세스 자신이 시스템의 자원을 낭비할 수 있고, 시스템이 프로세스가 종료될 때까지 추적을 해야 하기 때문에 성능 저하의 원인이 된다.
고아 프로세스는 init 프로세스가 관리를 해 주지만 성능 저하를 방지하기 위해 부모 프로세스가 종료되기 전에 모든 자식 프로세스를 wait 해 주는 것이 좋다.
요즘에는 사람들이 NAS를 많이들 활용하고 있다. NAS는 Network Attached Storage의 약자로 네트워크에 연결된 저장장치로 사람들이 흔히 쓰는 클라우드의 기능을 하고 있는 일종의 서버이다.
단순히 클라우드 서비스와 같이 저장소로 활용을 많이 하고 있지만, 그 뿐만이 아닌 서버 운영, DB, 공유 등의 다양한 기능을 제공하기도 한다. 또한 어디서든 외장하드 같은 것을 번거롭게 들고 다니지 않아도 된다. 이 부분이 내가 NAS를 구매한 이유 중 하나이다.
사실 NAS를 구매한건 22년 05월로 사용한지는 벌써 반년이 지났지만 이제서야 글로 작성하면서 사용했던 방식이나 활용법을 글로 적어보려고 한다…ㅎ 구매한 이유는 가족들의 사진을 저장하고 어디서든 공유하면서 사용하기 위한 목적이 우선적이면서 무료 클라우드가 가득 찼기에 매달 요금을 내면서 사용하기 싫었기 때문에 큰 출혈이 있더라고 구매하였다.
그러면서 더더욱 욕심을 내며 사이드 프로젝트를 위한 서버로도 활용하면 좋을 것 같다는 생각을 했기 때문에 관련 기능을 지원하는 NAS를 찾아보았다. (실제로 이 글을 쓰는 지금 서버로 활용하여 개발한 프로젝트가 2~3개는 된다.)
Synology
여러가지 장비를 비교하며 찾아보다가 Synology 사의 장비를 구매하기로 결정했다. 그 이유는 DSM센터를 통해서 사용하기 편리한 UI를 제공하고 있으며, Synology사의 다양한 내부 패키지 기능을 활용하면 사용 범위성이 무궁무진하기 때문이다.
현재 구매한 NAS는 DS220+ 2Bay 제품으로, 가격적으로도 그렇고 내가 원하는 기능 정도로만 사용하기에 적당한 제품이다.
프로젝트를 진행하게 되면 단순히 자신이 작성한 코드만으로 개발하는 것이 아니라 많은 라이브러리들을 활용해서 개발을 하게 된다. 세상에 많은 천재들이 개발한 라이브러리를 활용해서 개발을 하게 되면 개발 시간도 단축될뿐 아니라 안정성도 그만큼 보장되지 않겠는가! 적극 활용한다!👍
이 때 사용되는 라이브러리들의 수가 수십개가 훌쩍 넘어가버리는 일이 발생해 이 많은 라이브러리들을 관리하는 것이 힘들어지는 경우가 종종 발생하게 된다. Maven은 이러한 문제를 해결해 줄 수 있는 도구이다. Maven은 내가 사용할 라이브러리 뿐만 아니라 해당 라이브러리가 작동하는데 필요한 다른 라이브러리들까지 관리하여 네트워크를 통해 자동으로 다운 받아 준다.
Maven은 프로젝트의 전체적인 라이프사이클을 관리하는 도구이며, 많은 편리함과 이점이 있어 널리 사용되고 있다. Maven은 JDK설치와 같이 설치할 수 있다. 환경변수를 잡아주면 cmd에서 mvn -version을 통해 버전을 알 수 있고 설치가 가능하다. 설치는 메이븐 홈페이지에서 할 수 있다.
Maven의 Lifecycle
maven 에서는 미리 정의하고 있는 빌드 순서가 있으며 이 순서를 라이프사이클이라고 한다. 라이프 사이클의 각 빌드 단계를 Phase라고 하는데, 이런 Phase들은 의존관계를 가지고 있다.
Clean : 이전 빌드에서 생성된 파일들을 삭제하는 단계
Validate : 프로젝트가 올바른지 확인하고 필요한 모든 정보를 사용할 수 있는지 확인하는 단계
Compile : 프로젝트의 소스코드를 컴파일하는 단계
Test : 단위 테스트를 수행하는 단계
테스트 실패 시, 빌드 실패로 처리
스킵 가능
Package : 실제 컴파일된 소스 코드와 리소스들을 jar등의 배포를 위한 패키지로 만드는 단계
Verify : 통합테스트 결과에 대한 검사를 실행하여 품질 기준을 충족하는지 확인하는 단계
Install : 패키지를 로컬 저장소에 설치하는 단계
Site : 프로젝트 문서를 생성하는 단계
Deploy : 만들어진 Package를 원격 저장소에 release하는 단계
위 9개의 라이프 사이클 말고도 더 많은 종류가 존재한다. 이를 크게 Clean, Build, Site 세 가지로 나누고 있다. 각 단계를 모두 수행하는 것이 아니라 원하는 단계까지만 수행할 수도 있으며 test단계는 큰 프로젝트의 경우에 몇 시간이 소요될 수 있으니 수행하지 않도록 스킵이 가능하다.
Phase와 Goal
위에서 잠깐 언급헀던 Phase는 Maven의 Build LifeCycle의 각각의 단계를 의미한다. 각각의 Phase는 의존관계를 가지고 있어서 해당 Phase가 수행되려면 선행 단계의 Phase가 모두 수행되어야 한다.
메이븐에서 제공되는 모든 기능은 플러그인 기반으로 동작하는데 메이븐은 라이프 사이클에 포함 되어있는 Phase마저도 플러그인을 통해 실질적인 작업이 수행된다. 즉 각가의 Phase는 어떤 일을 할지 정의하지 않고 어떤 플러그인의 Goal을 실행할지 설정한다.
메이븐에서는 하나의 플러그인에서 여러작업을 수행할 수 있도록 지원하며, 플러그인에서 실행할 수 있는 각각의 기능을 Goal이라고 한다. 플러그인의 Goal을 실행하는 방법은 다음과 같다.
mvn groupId:artifactId:version:goal (아래와 같이 생략 가능)
mvn plugin:goal
POM(Project Object Model)
pom은 이름 그대로 Project Object Model의 정보를 담고 있는 파일이다. 이 파일에서 주요하게 다루는 기능들은 다음과 같다.
프로젝트 정보 : 프로젝트의 이름, 개발자 목록, 라이센스 등
빌드 설정 : 소스, 리소스, 라이프 사이클별 실행한 플러그인(Goal)등 빌드와 관련된 설정
빌드 환경 : 사용자 환셩 별로 달라질 수 있는 프로파일 정보
POM연관 정보 : 의존 프로젝트(모듈), 상위 프로젝트, 포함하고 있는 하위 모듈 등
POM은 pom.xml파일을 말하며 Maven의 기능을 이용하기 위해 사용된다.
Gradle 이란?
Gradle이란 기본적으로 빌드 배포 도구(Build Tool)이다. 안드로이드 앱을 개발할때 필요한 공식 빌드시스템이기도 하며 JAVA, C/C++, Python 등을 지원한다.
빌드툴인 Ant Builder와 그루비 스크립트를 기반으로 구축되어 기존 Ant의 역할과 배포 스크립트의 기능을 모두 사용가능하다.
Maven의 경우 XML로 라이브러리를 정의하고 활용하도록 되어 있으나, Gradle의 경우 별도의 빌드스크립트를 통하여 사용할 어플리케이션 버전, 라이브러리등의 항목을 설정 할 수 있다.
장점으로는 스크립트 언어로 구성되어 있기 때문에 XML과 달리 변수선언, if else for 등의 로직이 구현 가능하여 간결하게 구성이 가능하다.
라이브러리 관리 : Maven repository를 동일하게 사용할 수 있어서 설정된 서버를 통하여 라이브러리를 다운로드 받아 모두 동일한 의존성을 가진 환경을 수정할 수 있다. 또한 자신이 추가한 라이브러리도 repo 서버에 올릴 수 있다.
프로젝트 관리 : 모든 프로젝트가 일관된 디렉토리 구조를 가지고 빌드 프로세스를 유지하도록 도와준다.
단위 테스트 시 의존성 관리 : junit 등을 사용하기 위해서 명시한다.
Gradle 장점
Maven에는 Gradle과 비교문서가 없지만, Gradle에는 비교문서가 있다. 그만큼 Maven의 모든 기능을 포함하고 있고, 더 뛰어나다고 표현하는것일까? Gradle이 시기적으로 늦게 나온만큼 사용성, 성능 등 비교적 뛰어난 스펙을 가지고 있다.
그래서 Gradle이 Maven보다 좋은점은?
Build라는 동적인 요소를 XML로 정의하기에는 어려운 부분이 많다.
설정 내용이 길어지고 가독성이 떨어짐
의존관계가 복잡한 프로젝트 설정하기에는 부적절
상속구조를 이용한 멀티 모듈 구현
특정 설정을 소수의 모듈에서 공유하기 위해서는 부모 프로젝트를 생성하여 상속하게 해야함 (상속의 단점이 생김)
Gradle은 그루비를 사용하기 때문에, 동적인 빌드는 Groovy 스크립트로 플러그인을 호출하거나 직접 코드를 짜면 된다.
Configuration Injection 방식을 사용해서 공통 모듈을 상속해서 사용하는 단점을 커버했다.
설정 주입시 프로젝트의 조건을 체크할 수 있어서 프로젝트별로 주입되는 설정을 다르게 할 수 있다.
Gradle은 Maven보다 최대 100배 빠르다고 한다.
그래서 결론은?
Gradle이 출시되었을 때는 Maven이 지원하는 Scope를 지원하지 않았고 성능면에서도 앞설것이 없었다. Ant의 유연한 구조적 장점과 Maven의 편리한 의존성 관리 기능을 합쳐놓은 것만으로도 많은 인기를 얻었던 Gradle은 버전이 올라가며 성능이라는 장점까지 더해지면서 대세가 되었다.
리드미컬하게 테스트를 진행하고 민첩한 지속적 배포를 생각하고 있다면 새로운 배움이 필요하더라도 Gradle을 사용하는것이 좋다고 생각한다.
importjava.time.LocalDateTime;importjavax.persistence.Column;importjavax.persistence.MappedSuperclass;importorg.hibernate.annotations.CreationTimestamp;importlombok.Data;// Getter, Setter Auto Create@Data// 공통 매핑 정보가 필요할 때, 부모 클래스에 선언하고 속성만 상속 받아서 사용하고 싶을 때 사용한다.@MappedSuperclasspublicabstractclassCommonVo{// register idprivateStringregId;// modify idprivateStringmodId;// register Date time@CreationTimestamp/*
* 보통 JPA는 SAVE시에 모든 칼럼을 INSERT한다.
* 그럴 경우, NOT NULL로 설정된 칼럼은 기본값으로 삽입되는 것이 아닌 NULL로 삽입을 시도한다.
* 이로 인해 에러가 발생하는데, 이럴 경우에 아예 쿼리에서 빼버려서 실행이 안되게 만들 수 있다.
* 쿼리에서 제외된 칼럼은 DB에 지정된 default값으로 삽입이 된다.
* 특정 칼럼을 제외하고 save하는 방법은 다음과 같다.
* insertable = false, updatable = false
*/@Column(updatable=false)privateLocalDateTimeregDtm;// modify Date time@CreationTimestampprivateLocalDateTimemodDtm;}
4. CommonVo를 상속받은 MemberVo 작성
MemberVo.java
importjavax.persistence.Entity;importjavax.persistence.GeneratedValue;importjavax.persistence.GenerationType;importjavax.persistence.Id;importcom.melon.boot.common.vo.CommonVo;importlombok.Data;// Getter, Setter Auto Create@Data@Entity(name="member")publicclassMemberVoextendsCommonVo{@Id@GeneratedValue(strategy=GenerationType.IDENTITY)privateLongmbrSeq;privateStringid;privateStringpwd;privateStringname;privateStringaddrLoad;}
사실 사이드 프로젝트를 시작하려고 생각하고 메모 했던 내용은 늘 있었다. 그럼에도 시간이 없다는 핑계로.. 아이디어가 없다는 핑계로.. 처음부터 만들어 볼 여유가 좀처럼 생기지 않았다. 그래도 뭔가 작은 프로젝트를 만들기 시작하고, 회사 일에도 여유가 생기고부터 만들어보고 싶었던것들을 리스트화하고 이것을 정리하면서 만들어갈 필요성을 느꼈다. 뭐, 이것도 결국에는 내 경험치가 될 것이니까?
사이드 프로젝트 계획
리스트 업
실현 가능성을 기반으로 우선순위 정리
설계
프로젝트 별 관리
리스트 업
중간 중간 생각나는대로 리스트업을 업데이트 할 예정인데 우선 정리한것들은 이렇다.
NAS Note에 정리한 아이디어의 일부인데 진작에 좀 활용할껄 너무 늦은거 아니니..
계획
우선적으로 포토샵을 아직 배우는중이기 때문에 UI작업이 제일 까다롭지 않을것 같은 로또앱을 출시해보려고 한다. 해당 내용은 다른 포스트로 업로드 할 예정이다.