이 디렉토리에는 자바에 대해서 공부하고 내용을 정리하면서 내가 이해한 내용을 작성하는 저장소이다.
자바는 내가 학부 생활을 시작하면서 지금까지 꾸준히 사용하고 있는 언어이다. 객체지향이라는 개념을 배우면서부터 자바의 매력에 빠졌고, 이것을 배우면서 공모전에도 나갈 수 있을 정도로 실력을 키워보기도하고 SPRING을 배우면서 자바의 다른 매력에 대해서도 공부해본 경험이 있다.
또한, 알고리즘을 자바로 하면서 지금까지 공부했던 내용을 잊기 전에 다시 한 번 정리해보자고 생각이 들어서 이 카테고리를 만들었다.
정리하면서 잊고 있었던 내용이나 부족했던 지식에 대해서 깨닫고 배우며 꽉 채울 수 있었으면 한다.
초기에 {0}, {1}, {2}, … {n} 이 각각 n+1개의 집합을 이루고 있다. 여기에 합집합 연산과, 두 원소가 같은 집합에 포함되어 있는지를 확인하는 연산을 수행하려고 한다.
집합을 표현하는 프로그램을 작성하시오.
입력(Input)
첫째 줄에 n(1 ≤ n ≤ 1,000,000), m(1 ≤ m ≤ 100,000)이 주어진다. m은 입력으로 주어지는 연산의 개수이다. 다음 m개의 줄에는 각각의 연산이 주어진다. 합집합은 0 a b의 형태로 입력이 주어진다. 이는 a가 포함되어 있는 집합과, b가 포함되어 있는 집합을 합친다는 의미이다. 두 원소가 같은 집합에 포함되어 있는지를 확인하는 연산은 1 a b의 형태로 입력이 주어진다. 이는 a와 b가 같은 집합에 포함되어 있는지를 확인하는 연산이다. a와 b는 n 이하의 자연수 또는 0이며 같을 수도 있다.
출력(Output)
1로 시작하는 입력에 대해서 한 줄에 하나씩 YES/NO로 결과를 출력한다. (yes/no 를 출력해도 된다)
2. 문제 풀이
이 문제는 이전에 SSAFY를 다니면서 알고리즘 수업 시간에 배웠던 union, find 방법을 활용해서 문제를 풀어볼 수 있었다.
오랜된 기억이라서 처음에는 헤매기도 했지만 정리해둔 내용을 다시 생각해보며 더듬어가면서 풀었다.
union, find 방법에 대해서 다시 한 번 정리하자면 체크 할 멤버들의 수의 배열에 해당 연관이 있는지 표시를 하고, 같은 그룹인지 아닌지 확인 할 수 있는 방법이다.
이 문제에서의 조건은 0 입력이 들어오면 find로 찾아서 union으로 묶고, 1 입력이 들어오면 find로 찾아서 표출해 주라고 한다.
[0][1][2][3][4][5]
-1 -1 -1 -1 -1 -1
처음에는 그룹이 없다고 하여 위와 같이 세팅을 한다.
부모 배열을 선언하고 union, find의 방법을 각각 정의 한다.
union은 같은 그룹인지 먼저 찾아봐야 하므로 find를 먼저 정의해보자.
찾고자하는 수의 배열 위치를 확인하여 해당 그룹이 존재하면 재귀의 방법으로 최종 root를 찾는다.
[0][1][2][3][4][5]
-1 -1 -1 1 -1 3
find(5);
-> 5를 find 하면 해당 부모 배열에서 3을 찾을 수 있다.
그러면 3을 다시 find한다.
find(3)
-> 3을 find 하면 부모 배열에서 1을 찾을 수 있다.
그러면 1을 다시 find한다.
find(1)
-> 1을 find하면 -1 즉, 최상단 부모라는 뜻이된다.
그러면 1-3-5 의 트리와 같은 구조로 그룹을 그려 볼 수 있게 된다.
위와 같이 find의 방법을 설명했다면 이번에는 union을 알아본다.
[0][1][2][3][4][5]
-1 -1 -1 1 2 3
union(4, 5)가 되면 각각의 4와 5의 최상단을 find로 찾아낸다.
find(5) => 1 || find(4) => 2
가 되는 것을 볼 수 있다.
이 둘은 다른 그룹이기 때문에 합칠 수 있다. 각각의 루트를 찾았기 때문에 이제 어느 한 쪽의 루트를 다른쪽의 루트의 자식으로 넣어주기만 하면 된다. 1을 2의 자식으로 넣게되면 parents[1] = 2 가 되겠다.
그러면 결국 union 후의 모습은 논리적으로 아래와 같을 것이다.
[0] [1] [2] [3] : depth
2 - 1 - 3 - 5
- 4
이러한 방식을 이용하여 집합을 표현하고 묶어줄 수 있다.
그럼 이것을 활용하여 코드로 표현해보자.
importjava.io.BufferedReader;importjava.io.IOException;importjava.io.InputStreamReader;importjava.util.Arrays;importjava.util.StringTokenizer;publicclassSetRepre_1717{staticint[]parents;privatestaticbooleanunion(inta,intb){intaRoot=find(a);intbRoot=find(b);if(aRoot!=bRoot){parents[bRoot]=aRoot;returntrue;}returnfalse;}privatestaticintfind(inta){if(parents[a]<0)returna;returnparents[a]=find(parents[a]);}publicstaticvoidmain(String[]args)throwsIOException{BufferedReaderbr=newBufferedReader(newInputStreamReader(System.in));StringTokenizerst=newStringTokenizer(br.readLine());intn=Integer.parseInt(st.nextToken());intm=Integer.parseInt(st.nextToken());parents=newint[n+1];Arrays.fill(parents,-1);for(inti=0;i<m;i++){if(!st.hasMoreTokens())st=newStringTokenizer(br.readLine());// 합집합은 0 a b의 형태로 입력이 주어진다. 이는 a가 포함되어 있는 집합과, b가 포함되어 있는 집합을 합친다는 의미intcondition=Integer.parseInt(st.nextToken());inta=Integer.parseInt(st.nextToken());intb=Integer.parseInt(st.nextToken());if(condition==0){union(a,b);}else{// 두 원소가 같은 집합에 포함되어 있는지를 확인하는 연산은 1 a bif(find(a)==find(b))System.out.println("YES");elseSystem.out.println("NO");}}}}
N개의 자연수가 입력되면 각 자연수를 뒤집은 후 그 뒤집은 수가 소수이면 그 소수를 출력하 는 프로그램을 작성하세요. 예를 들어 32를 뒤집으면 23이고, 23은 소수이다. 그러면 23을 출 력한다. 단 910를 뒤집으면 19로 숫자화 해야 한다. 첫 자리부터의 연속된 0은 무시한다.
입력(Input)
첫 줄에 자연수의 개수 N(3<=N<=100)이 주어지고, 그 다음 줄에 N개의 자연수가 주어진다. 각 자연수의 크기는 100,000를 넘지 않는다.
일단 틸트(~)에 대해서 알아보자. NPM문서에 따르면 npm을 사용할 때 package.json에서 버전 명시를 다음과 같이 할 수 있다.
1.2.3
>1.2.3
>=1.2.3
<1.2.3
<=1.2.3
~1.2.3
여기서 가장 많이 사용하는 방식이 틸트(~) 방식이고, npm install MODULE --save나 npm install MODULE --save-dev를 사용하면 자동으로 package.json에 의존성을 추가 할 수 있는데, 이 때 기본으로 사용하는 방법이 틸트(~) 방식이다. 틸트는 간단히 말하자면 현재 지정한 버전의 마지막 자리 내의 범위에서만 자동으로 업데이트 한다.
~0.0.1 : >=0.0.1 <0.1.0
~0.1.1 : >=0.1.1 <0.2.0
~0.1 : >=0.1.0 <0.2.0
~0 : >=0.0 <0.1
그래서 다양한 방식으로 버전을 명시했을 때 위와 같은 범위내에서 자동으로 업데이트를 한다.
캐럿(^)
그러면 캐럿(^)은 틸트와 어떻게 다를까?
캐럿을 설명하기 이전에 먼저 SemanticVersioning (보통 SemVer라고 부른다)에 대해서 알아야 하는데, Node.js도 그렇고 npm 모듈들은 모두 SemVer를 따르고 있다. SemVer는 MAJOR.MINOR.PATCH의 버저닝을 따르는데 각 의미는 다음과 같다.
주 버전(Major Version): 기존 버전과 호환되지 않게 변경한 경우
MAJOR version when you make incompatible API changes
부 버전(Minor version): 기존 버전과 호환되면서 기능이 추가된 경우
MINOR version when you add functionality in a backwards-compatible manner
수 버전(Patch version): 기존 버전과 호환되면서 버그를 수정한 경우
PATCH version when you make backwards-compatible bug fixes
즉, MAJOR 버전은 API의 호환성이 깨질만한 변경사항을 의미하고 MINOR 버전은 하위호환성을 지키면서 기능이 추가된 것을 의미하고 PATCH 버전은 하위호환성을 지키는 범위내에서 버그가 수정된 것을 의미한다.
캐럿(^)은 Node.js의 모듈이 이 SemVer의 규약을 따르는 것을 신뢰한다는 가정하에 동작한다. 그래서 MINOR나 PATCH버전은 하위호환성이 보장되어야 하므로 업데이트를 한다.
^1.0.2 : >=1.0.2 <2.0
^1.0 : >=1.0.0 <2.0
^1 : >=1.0.0 <2.0
그래서 캐럿을 사용했을 때에는 위와 같이 동작한다. 틸트와 비교해보면 차이점이 명확한데, 1.x.x 내에서는 하위호환성이 보장되므로 그 내에서는 모두 업데이트 하겠다는 의미이다.
하지만! 여기에는 예외사항이 있다.
^0.1.2 : >=0.1.2 <0.2.0
^0.1 : >=0.1.0 <0.2.0
^0 : >=0.0.0 <1.0.0
^0.0.1 : ==0.0.1
버전이 1.0.0 미만인 경우에는 (SemVer에서는 pre-releases라고 부른다) 상황이 다르다. 소프트웨어 대부분에서 1.0 버전을 내놓기 전에는 API 변경이 수시로 일어난다. 그래서 0.1을 사용하다가 0.2를 사용하면 API가 모두 달려졌을 수 있다. 그래서 캐럿(^)을 사용할 때, 0.x.x에서는 마치 틸트처럼 동작해서 지정한 버전 자릿수 내에서만 업데이트한다. 그리고 0.0.x인 경우에는 하위호환성이 보장되지 않을 가능성이 높으므로 위의 마지막 예시처럼 지정한 버전만을 사용한다.
캐럿에 대한 오류!
캐럿은 동작방식을 이해하면 수긍 할만하다.(물론 배포용으로는 어렵지만 이건 틸드도 마찬가지) 하지만 약간 복잡한 부분이 있어서 그냥 틸드를 쓰고자 할 수도 있는데 그럼에도 캐럿의 존재 정도는 알고 있어야 한다. 캐럿은 근래에 추가된 기능이므로 과거 버전의 npm은 캐럿을 이해하지 못한다.(정확히 어느 버전부터 추가되었는지 찾지 못헀다) 그래서 캐럿이 없는 구 버전의 npm에서 캐럿을 사용하면 오류가 발생한다.
구문을 이해하지 못하므로 버전을 찾지 못하고 “Error: No compatible version found”이라는 설치 오류가 발생한다. 이는 npm install -g npm을 통해서 npm을 최신 버전으로 올리면 해결할 수 있다. 캐럿을 모른 상태에서 저 오류를 보면 좀 당황스러울수 있다.
npm v1.4.3부터는 npm install MODULE --save나 npm install MODULE --save-dev를 사용했을 때 기본값이 틸드 대신 캐럿이 되었기 때문에 틸드를 사용하고자 한다면 매번 직접 수정해야 한다. 그리고 본인은 틸드방식을 사용하더라도 참조한 모듈이 다른 모듈을 참조할 때 캐럿을 사용할 수도 있으므로 npm을 최신 버전으로 업데이트하지 않으면 결국 오류가 나서 제대로 설치가 안 될 것이다.
직선 도로상에 왼쪽부터 오른쪽으로 1번부터 차례대로 번호가 붙여진 마을들이 있다. 마을에 있는 물건을 배송하기 위한 트럭 한 대가 있고, 트럭이 있는 본부는 1번 마을 왼쪽에 있다. 이 트럭은 본부에서 출발하여 1번 마을부터 마지막 마을까지 오른쪽으로 가면서 마을에 있는 물건을 배송한다.
각 마을은 배송할 물건들을 박스에 넣어 보내며, 본부에서는 박스를 보내는 마을번호, 박스를 받는 마을번호와 보낼 박스의 개수를 알고 있다. 박스들은 모두 크기가 같다. 트럭에 최대로 실을 수 있는 박스의 개수, 즉 트럭의 용량이 있다. 이 트럭 한대를 이용하여 다음의 조건을 모두 만족하면서 최대한 많은 박스들을 배송하려고 한다.
조건 1: 박스를 트럭에 실으면, 이 박스는 받는 마을에서만 내린다.
조건 2: 트럭은 지나온 마을로 되돌아가지 않는다.
조건 3: 박스들 중 일부만 배송할 수도 있다.
마을의 개수, 트럭의 용량, 박스 정보(보내는 마을번호, 받는 마을번호, 박스 개수)가 주어질 때, 트럭 한 대로 배송할 수 있는 최대 박스 수를 구하는 프로그램을 작성하시오. 단, 받는 마을번호는 보내는 마을번호보다 항상 크다.
예를 들어, 트럭 용량이 40이고 보내는 박스들이 다음 표와 같다고 하자.
보내는 마을
받는 마을
박스 개수
1
2
10
1
3
20
1
4
30
2
3
10
2
4
20
3
4
20
이들 박스에 대하여 다음과 같이 배송하는 방법을 고려해 보자.
(1) 1번 마을에 도착하면
다음과 같이 박스들을 트럭에 싣는다. (1번 마을에서 4번 마을로 보내는 박스는 30개 중 10개를 싣는다.)
보내는 마을
받는 마을
박스 개수
1
2
10
1
3
20
1
4
30
(2) 2번 마을에 도착하면
트럭에 실려진 박스들 중 받는 마을번호가 2인 박스 10개를 내려 배송한다. (이때 트럭에 남아있는 박스는 30개가 된다.)
그리고 다음과 같이 박스들을 싣는다. (이때 트럭에 실려 있는 박스는 40개가 된다.)
보내는 마을
받는 마을
박스 개수
2
3
10
(3) 3번 마을에 도착하면
트럭에 실려진 박스들 중 받는 마을번호가 3인 박스 30개를 내려 배송한다. (이때 트럭에 남아있는 박스는 10개가 된다.)
그리고 다음과 같이 박스들을 싣는다. (이때 트럭에 실려 있는 박스는 30개가 된다.)
보내는 마을
받는 마을
박스 개수
3
4
20
(4) 4번 마을에 도착하면
받는 마을번호가 4인 박스 30개를 내려 배송한다.
위와 같이 배송하면 배송한 전체 박스는 70개이다. 이는 배송할 수 있는 최대 박스 개수이다.
입력(Input)
입력의 첫 줄은 마을 수 N과 트럭의 용량 C가 빈칸을 사이에 두고 주어진다. N은 2이상 2,000이하 정수이고, C는 1이상 10,000이하 정수이다. 다음 줄에, 보내는 박스 정보의 개수 M이 주어진다. M은 1이상 10,000이하 정수이다. 다음 M개의 각 줄에 박스를 보내는 마을번호, 박스를 받는 마을번호, 보내는 박스 개수(1이상 10,000이하 정수)를 나타내는 양의 정수가 빈칸을 사이에 두고 주어진다. 박스를 받는 마을번호는 보내는 마을번호보다 크다.
출력(Output)
트럭 한 대로 배송할 수 있는 최대 박스 수를 한 줄에 출력한다.
서브태스크
번호
배점
제한
1
15
보내는 마을번호는 모두 1, N ≤ 20
2
17
받는 마을번호는 N-1 또는 N, 3 ≤ N ≤ 20
3
20
N ≤ 5, M ≤ 5, C ≤ 10
4
23
N ≤ 100, M ≤ 1,000, C ≤ 2,000
5
25
추가적인 제약조건은 없다.
2. 문제 풀이
처음에 그냥 그리디적 가벼운 접근으로 해결하려고 하니 답이 나오지 않았다. 주어진 조건에서 택배의 거리로 짧은 순서대로 정렬하고 현 위치에서 싣을 수 있는 가장 많은 택배만큼 싣고 가려고 했었다.
그러나 그렇게 접근하니 예외처리를 해야하는 부분에서 오류가 발생하였다.
몇 시간을 헤매이다가 결국에는 힌트를 보고서 문제를 해결 할 수 있었다.
마을 별로 내리는 짐의 개수 대신에 K 마을에 방문해서 짐을 내린 후, 트럭에 싣고 있는 박스의 개수를 파악한다.
보내는 마을과 받는 마을의 거리가 멀수록 보내는 마을로부터 다음 마을들을 순차적으로 방문할 때마다 받는 마을 바로 직전의 마을까지 짐을 계속해서 들고 있어야 한다.
그 사이에 더 큰 짐을 싣고 내리는 경우가 있을 수 있기 때문에 보내는 마을과 받는 마을의 거리가 멀면 그만큼 손해를 볼 수 있다.
‘무조건 1번 마을부터 N번 마을까지 순차적으로 방문한다는 조건’ & ‘보내는 마을보다 무조건 받는 마을의 번호가 높다는 조건’ 이 두 조건을 활용하는 것으로 문제를 풀 수 있다.
그렇다면 보내는 마을이 받는 마을과 거리가 가깝다는 뜻은 받는 마을의 번호를 오름차순으로 정렬했을 때 가장 앞에 있을수록 가깝다는 뜻이 된다.
그 다음 우선순위로는 보내는 마을을 오름차순으로 정렬하는 것이다. ** 두 번째 우선순위는 굳이 안해도 풀 수 있다.
즉! 아래의 단계로 해결 할 수 있었다.
받는 마을 번호를 오름차순으로 정렬
각 마을 별로 박스의 개수를 파악할 수 있는 Array 생성
앞에서부터 (보내는 마을, 받는 마을, 박스 개수) 를 꺼내서 사용 ** 참고로, 받는 마을에서 박스 개수는 고려하지 않는다. 도착하면 박스를 내리기 때문에
트럭의 용량 : 40 마을 : 1 // 2 // 3 // 4 마을에서의 트럭에 싣은 박스 개수 : 30 // 40(+10) // 30(+ 10) // 0 ( + 10 내림 = 70) ** 트럭의 용량이 40이기 때문에 2번 마을에 박스가 20개나 있음에도 불구하고 10만 싣을 수 있다. ** 3번 마을에는 2번에서 10만 싣었으니 당연히 10이 추가된다.
요즘 사람들은 궁금한 것에 대한 답을 대부분 Naver, Google 등에 검색하여 답을 얻곤 합니다. 그렇기 때문에 당연히 모든 비즈니스 및 웹사이트 소유주들은 Google에서 자신들의 정보를 사람들이 찾기 쉽도록 만들기 위해서라면 할 수 있는 모든 것을 하고 있습니다. 검색 결과에서 상위에 노출될 수 있도록 내 콘텐츠를 최적화하는 방식 즉, 이것이 바로 SEO입니다.
성공적인 SEO를 수행하기 위한 첫 번째 단계는 간편한 사용자 지정과 콘텐츠 업데이트를 지원하고, 사이트 요소를 최적화하는 데 필요한 도구를 제공하는 플랫폼을 통해 웹사이트를 제작하는 것입니다. Wix와 같은 웹사이트 제작 도구를 활용해 보세요. 간편하게 사이트를 업데이트 할 수 있으며, SEO 도구가 내장되어 있어 편리합니다.
사이트의 토대가 얼추 지어졌다면 순위 향상에 도움이 되는 메타데이터, 링크와 같은 세부 사항을 신경 써야 합니다. 지금부터 이러한 세부 사항을 시행하기 위해 무엇이 필요한지, 세부사항들이 SEO 표준을 충족하는지 살펴보도록 하겠습니다.
SEO 란?
SEO(검색 엔진 최적화)는 웹사이트가 유기적인(무료) 검색 방식을 통해 검색 엔진에서 상위에 노출될 수 있도록 최적화하는 과정을 말합니다. 비즈니스 유형이 어떤 것이든 SEO는 가장 중요한 마케팅 유형 중 하나입니다.
왜냐하면 Google은 검색하는 사람들에게 긍정적인 사용자 경험을 선사하는 것이 목표이기 때문에 가능한 한 최고의 정보를 제공하길 원합니다. 따라서, SEO 노력은 검색 엔진이 여러분의 콘텐츠를 특정 검색어에 대한 웹 상의 주요한 정보로 인식하도록 하는 과정에 포커스를 맞추어야 합니다.
SEO는 어떻게 이루어지나?!
검색 엔진은 웹페이지가 어떤 콘텐츠를 가지고 있는지, 해당 페이지가 무엇에 대한 것인지 판단하기 위해 인터넷을 통하여 웹페이지를 크롤링하는 로봇인 웹 크롤러를 사용합니다. 웹 크롤러는 코드를 스캔하여 웹페이지에 표시되는 텍스트, 이미지, 동영상을 등을 수집하여 가능한 모든 정보를 얻습니다. 웹 크롤러가 각 페이지에서 사용할 수 있는 정보 유형에 대한 충분한 정보를 수집하여 해당 내용이 검색자에게 유용하다고 판단하면 해당 페이지를 색인에 추가합니다. 여기서 말하는 색인은 본질적으로 검색 엔진이 잠재적인 검색자에게 제공하기 위해 저장한 모든 가능성 있는 웹 결과입니다.
검색 엔진은 검색자들이 찾고 있는 것뿐만 아니라 온라인에 이미 존재하는 다른 정보들을 기반으로 최상의 결과가 무엇인지 평가합니다. 검색자가 검색을 하면 알고리즘은 검색어를 색인의 관련 정보와 일치시켜 검색자가 입력한 검색어에 대한 정확한 답변을 제공합니다. 그 다음 플랫폼은 수백 개의 신호를 사용하여 각 검색자에게 표시될 콘텐츠 순서를 결정합니다. 그리고 SEO 전문가들은 이러한 신호들을 완벽하게 마스터하려고 합니다.
Google은 알고리즘이나 프로세스에 대한 자세한 사항을 공개하지 않기 때문에 어떤 요소가 색인화와 순위에 영향을 미치는지 정확하게 알 수 없다는 점을 아는 것이 중요합니다. 그러므로 SEO는 정확하게 맞아 떨어지는 과학이 아니며, 최적화를 완벽하게 구현한 것처럼 보이더라도 그에 대한 결과를 보기 위해서는 인내심이 필요하고, 지속적으로 조정을 해주어야 할 수 있습니다.
온-페이지 SEO vs 오프-페이지 SEO
무엇이 검색 엔진의 순위에 가장 큰 영향을 미치는지 정확히 알 방법이 없기 때문에 전문가들은 SEO 전략에는 다양한 전술을 포함하는 것을 권장합니다. 이러한 전술은 크게 On-page SEO와 Off-page SEO라는 두 가지 범주로 나눌 수 있습니다.
On-page SEO는 디자인 및 작성한 콘텐츠에서부터 메타데이터, 대체 텍스트 등에 이르기까지 웹페이지 자체에 구현하는 전략을 말합니다. Off-page SEO는 페이지의 외부에서 수행하는 단계를 말합니다. 여기에는 외부 링크, SNS 게시물, 다른 웹사이트 프로모션 방식 등이 포함됩니다.
On-page SEO 및 Off-page SEO 모두 내 사이트로 트래픽을 유도하고, 궁극적으로 내 사이트가 인터넷에서 중요한 참가자라는 신호를 Google에 보내기 위해 필수적입니다. 내 페이지들이 중요하고, 사람들이 내가 제공하는 것들을 아는 것에 관심이 있다는 것을 Google에 알림으로써 내 페이지가 상위에 노출되고, 더 많은 트래픽을 유도하도록 만들 수 있습니다.
Node.js는 백엔드를 구현하는 기술이라고 생각했던 때가 있었다. 그러나 요즘은 FE 공고에도 Node.js 기술이 우대사항이 되고 있는것을 볼 수 있었다. 웹 어플리케이션을 개발하는데 있어서 직접적으로 사용하는것은 아니지만 개발 환경을 구성하고 이해하는데에는 Node.js를 모른다면 언젠가 막히는 때가 온다고 한다.
1. 프론트엔드 개발에 Node.js가 필요한 이유
최신 스펙으로 개발 할 수 있다
자바스크립트 스펙의 빠른 발전에 비해 브라우져의 지원 속도는 항상 뒤쳐진다. 아무리 편리한 스펙이 나오더라도 이것을 구현해 주는 중간다리의 역할, 예를 들자면 바벨과 같은 도구의 도움 없이는 부족하다. 더불어 웹팩, NPM 같은 노드 기술로 만들어진 환경에서 사용할 때 비로소 자동화된 프론트엔드 개발 환경을 갖출 수 있다.
마찬가지로 Typescript, SASS 같은 고수준 프로그래밍 언어를 사용하려면 전용 트랜스파일러가 필요하다. 물론 이것 역시 Node.js 환경이 뒷받침 되어야 우리가 말하는 프론트엔드 개발 환경을 만들 수 있다.
빌드 자동화
과거처럼 코딩 결과물을 브라우져에 바로 올리는 경우는 흔치 않다고 한다. 파일을 압축하고, 코드를 난독화하고, 폴리필을 추가하는 등 개발 이외의 작업을 거친 후에야 배포를 하게 된다. Node.js는 이러한 일련의 빌드 과정을 이해하는데 많은 역할을 하고 있다. 또한 라이브러리 의존성을 해결하고, 각종 테스트를 자동화하는데도 사용된다.
개발 환경 커스터마이징
각 프레임워크에서 제공하는 도구를 사용하면 손쉽게 개발환경을 갖출 수 있도록 지원하고 있다. React.js의 CRA(create-react-app), Vuejs의 vue-cli를 사용한다면 손쉽게 개발환경을 갖출 수 있는 것이다. 그러나 개발 프로젝트는 각자의 목적이나 사용방법에 있어서 형편이라는 것이 있어서 툴을 그대로 사용할 수 없는 경우도 빈번하다. 어쩌면 자동화된 도구를 사용할 수 없는 환경이 다가올수도 있는데, 그 때에 직접 환경을 구축해야 할 수도 있다. 커스터마이징을 하려면 반드시 Node.js 지식이 필요하다.
위에서 배경하에 Node.js는 프론트엔드 개발에서 필수 기술로 자리매김하고 있다. 이번에는 Node.js 기술을 바탕으로 프론트엔드 개발 환경을 이해하고 직접 구성해보면 좋을 것 같다.
2. Node.js 설치
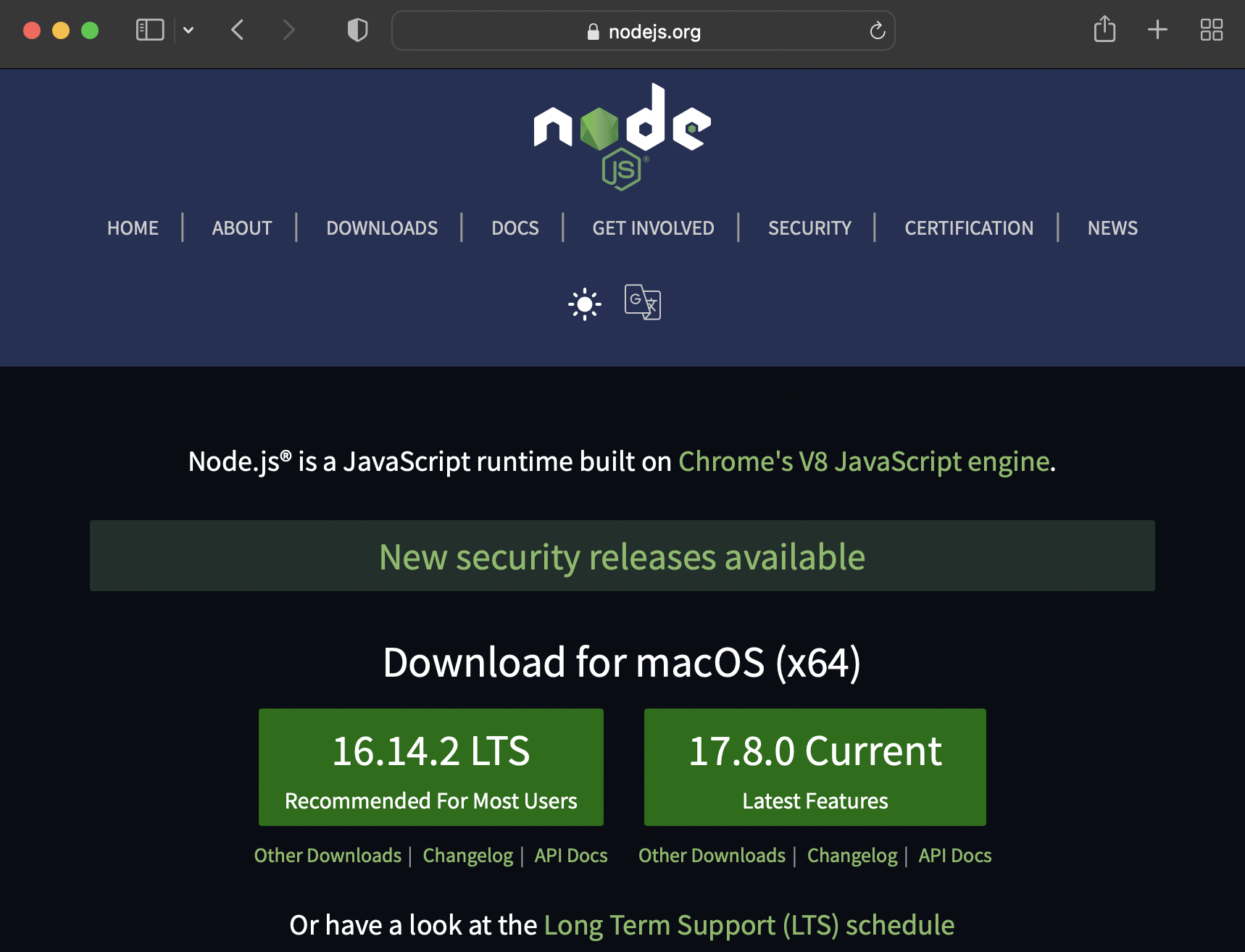
노드 설치는 무척 간단하다. 자신의 운영체제에 맞게 설치파일을 다운받으면 된다. Nodejs.org 사이트에서 노드 최신 버전을 다운로드 받아 보자.
두 가지 버전을 선택하여 설치할 수 있다. 왼쪽 짝수 버전, 오른쪽이 홀수 버전이다. 안정적이고 장기간 지원하는 것이 짝수 버전이고, 불안정할 수 있지만 최신 기능을 지원하는 것이 홀수 버전이다. 리눅스 배포버전과 비슷한 관례를 따른다고 한다.
짝수 버전 : 안정적, 신뢰도 높음 (LTS)
홀수 버전 : 최신 기능
이왕이면 오른쪽에 있는 최신 버전을 선택해서 다운로드 받아보자. 개발 환경에 대한 이해니까! (만약 Node.js로 서버를 구성하는 경우라면 어떤 버전을 사용할지 신중하게 선택해야 한다.)
설치화면이 나오고 버튼을 몇 번 클릭하면 아래 경로로 Node.js와 NPM이 설치가 완료된다.
Node.js : \usr\local\bin\node
NPM : \usr\local\bin\npm
설치가 완료된 후, 터미널을 열어서 명령어를 통해 확인해 볼 수 있다.
$ node
> 1 + 2
3
> 프롬프트와 함께 입력 대기화면이 나온다. 정수 계산이나 console.log() 같은 내용도 실행 할 수 있다.
이것을 노드 REPL(read-eval-print loop)이라고 부르는데, 자바스크립트 코드를 입력하고 즉시 결과를 확인할 수 있는 프로그램이다. 파이썬이나 PHP 같은 언어도 제공하는 기능이다.
.exit 명령을 실행하거나 ctrl + c를 연속 두 번 입력하면 REPL 프로그램에서 빠져 나올 수 있다.
이번에는 --version 옵션을 추가해서 설치된 버전을 확인해 본다.
$ node --version
v17.3.1
NPM(Node Package Manage)도 확인 할 수 있다.
$ npm
Usage: npm <command>
$ npm --version
8.3.0
이렇게 각 Node.js와 NPM을 설치하고 각 설치된 버전을 확인해 볼 수 있다.
3. 프로젝트 초기화
개발 프로젝트는 외부 라이브러리를 다운로드 받고 빌드하는 등 일련의 명령어를 자동화하여 프로젝트를 관리하는 도구가 존재한다. PHP의 컴포저(Composer)나 자바의 그래들(Gradle) 같은 툴이 그러한 프로그램이라고 할 수 있다. NPM은 자바스크립트 기반 프로젝트의 빌드 도구인 셈이다. NPM을 이용해 프론트엔드 개발 프로젝트를 세팅해보자.
3-1. INIT
NPM은 다양한 하위 명령어를 제공하는데, 그 중 init 명령어를 사용하면 프로젝트를 생성 할 수 있다.
위의 내용에서 볼 수 있듯이 패키지 이름, 버전 등 프로젝트와 관련된 정보들을 얻기 위한 몇 가지 질문들을 볼 수 있다. 빈칸으로 남겨 놓으면 괄호 안에 기본 값으로 세팅할 수 있다. 모든 질문에 답하면 명령어를 실행한 폴더에 package.json 파일이 생성된다. 모두 기본값으로 세팅하려면 npm init -y 명령어로 질문을 스킵하고 package.json 파일을 생성할 수 있다.
3-2. Package.json
Node.js는 package.json 파일에 프로젝트의 모든 정보를 기록한다.
name: 프로젝트 이름
version: 프로젝트 버전 정보
description: 프로젝트 설명
main: 노드 어플리케이션일 경우 진입점 경로. 프론트엔드 프로젝트일 경우 사용하지 않는다.
scripts: 프로젝트 명령어를 등록할 수 있다.초기화시 test 명령어가 샘플로 등록되어 있다
author: 프로그램 작성자
license: 라이센스
각 항목의 의미는 위의 내용과 같다.
## 4. 프로젝트 명령어 생성한 프로젝트는 package.json에 등록한 스크립트(script)를 이용해 실행한다. 어플리케이션 빌드, 테스트, 배포, 실행 등의 명령어를 등록하여 실행하는데에는 다음과 같다.
$ npm test
Error: no test specified
npm ERR! Test failed. See above for more details.
에러 메세지를 출력하고 그 다음 줄에 npm 에러가 발생한다. 이것은 npm 스크립트에 등록된 쉘 스크립트 코드를 실행했기 때문이다.
package.json
{"script":{"test":"echo \"Error: no test specified\" && exit 1"}}
echo 명령어로 메세지 “Error: no test specified”를 출력한뒤 에러 코드 1을 던지면서 종료하는 동작이다. 에러 코드 1을 확인하면 에러(“npm ERR!…“)를 출력하게된다.
CDN의 서버 장애로 인해 외부 라이브러리를 사용할 수 없다면 어떻게 될까?? 아무리 우리 어플리케이션 서버가 정상이더라도 필수 라이브러리를 가져오지 못한다면 웹 어플리케이션은 정상적으로 동작하지 않을 것이다.
5-2. 직접 다운로드 받는 방법
그렇다면 라이브러리 코드를 우리 프로젝트 폴더에 다운받아 놓는건 어떨까? CDN을 사용하지 않기 때문에 장애와 독립적으로 웹 어플리케이션을 제공할 수 있을 것 같다.
하지만 이런 상황도 있다. 라이브러리는 계속해서 업데이트 될 것이고, 우리 프로젝트에서도 최신 버전으로 교체해야 한다. 매번 직접 다운로드하는 것은 매우 귀찮은 일이 될 것이다. 버전에 따라 하위 호환성 여부까지 확인하려면 실수할 여지가 많다.
라이브러리를 어느 한 곳에서 업데이트하고 하위 호환되는 안전한 버전만 다운받아 사용할 수 있다면 어떨까?
5-3. NPM을 이용한 방법
NPM은 이런 방식으로 패키지를 관리한다. npm install 명령어로 외부 패키지를 우리 프로젝트 폴더에 다운로드 해보자.
$ npm install react
최신 버전의 react를 NPM 저장소에서 찾아 우리 프로젝트로 다운로드 하는 명령어다. package.json에는 설치한 패키지 정보를 기록한다.
{"dependencies":{"react":"^16.12.0"}}
버전 16.12.0을 설치했다는 의미이다.
5-4. 유의적 버전
“^16.12.0”이 의미하는 바는 무엇일까?
위 질문에 답하기 전에 버전 관리에 대해서 생각해 볼 필요가 있다. 만약 프로젝트에서 사용하는 패키지의 버전을 엄격하게 제한한다면 어떨까? 프로젝트를 버전업 하는데 꽤 힘들 수 있다. 사용하는 패키지를 전부 버전업해야 하기 때문이다. 어쩌면 우리 프로젝트는 현재 버전에 갇혀 버릴지도 모른다.
그럼 프로젝트에서 사용하는 패키지 버전을 느슨하게 풀어 놓으면 문제가 해결될까? 오히려 여러 버전별로 코드를 관리해야하는 혼란스러움을 겪게될 수 있다.
버전 번호를 관리하기 위한 규칙이 필요한데 이 체계를 “유의적 버전”이라고 한다. NPM은 이 유의적 버전(Sementic Version)을 따르는 전제 아래 패키지 버전을 관리한다.
유의적 버전은 주(Major), 부(Minor), 수(Patch) 세 가지 숫자를 조합해서 버전을 관리한다. 위에 설치한 react의 버전은 v16.12.0인데 주 버전이 16, 부 버전이 12, 수 버전이 0인 셈이다.
주 버전(Major Version): 기존 버전과 호환되지 않게 변경한 경우
부 버전(Minor version): 기존 버전과 호환되면서 기능이 추가된 경우
수 버전(Patch version): 기존 버전과 호환되면서 버그를 수정한 경우
5-5. 버전의 범위
NPM이 버전을 관리하는 방식은 유의적 버전 명시뿐만 아니라 버전의 범위를 자신만의 규칙으로 관리한다. 가장 단순한 것이 특정 버전을 사용하는 경우다.
1.2.3
특정 버전보다 높거나 낮은 범위를 나타내는 방법은 다음과 같다.
>1.2.3
>=1.2.3
<1.2.3
<=1.2.3
마지막으로 틸드(~)와 캐럿(^)을 이용해 범위를 명시한다.
~1.2.3
^1.2.3
틸트(~)는 마이너 버전이 명시되어 있으면 패치버전만 변경한다. 예를 들어 ~1.2.3 표기는 1.2.3 부터 1.3.0 미만 까지를 포함한다. 마이너 버전이 없으면 마이너 버전을 갱신한다. ~0 표기는 0.0.0부터 1.0.0 미만 까지를 포함한다.
캐럿(^)은 정식버전에서 마이너와 패치 버전을 변경한다. 예를 들어 ^1.2.3 표기는 1.2.3부터 2.0.0 미만 까지를 포함한다. 정식버전 미만인 0.x 버전은 패치만 갱신한다. ^0 표기는 0.0.0부터 0.1.0 미만 까지를 포함한다.
보통 라이브러리 정식 릴리즈 전에는 패키지 버전이 수시로 변한다. 0.1에서 0.2로 부버전이 변하더라도 하위 호환성을 지키지 않고 배포하는 경우가 빈번하다. ~0로 버전 범위를 표기한다면 0.0.0부터 1.0.0미만까지 사용하기 때문에 하위 호완성을 지키지 못하는 0.2로도 업데이트 되어버리는 문제가 생길수 있다.
반면 캐럿을 사용해 ^0.0으로 표기한다면 0.0.0부터 0.1.0 미만 내에서만 버전을 사용하도록 제한한다. 따라서 하위 호완성을 유지할 수 있다. (자세한 내용은 여기를 참고)
NPM으로 패키지를 설치하면 package.json에 설치한 버전을 기록하는데 캐럿 방식을 이용한다. 초기에는 버전 범위에 틸트를 사용하다가 캐럿을 도입해서 기본 동작으로 사용했다. 그래서 우리가 설치한 react는 ^16.12.0 표기로 버전 범위를 기록한 것이다.
6. 정리
Node.js 기술을 기반으로 하는 프로트엔드 개발 환경 구축을 위해 Node.js와 NPM을 설치했다.
npm init 명령어를 사용하면 package.json에 정보를 기록하고 프로젝트를 초기화 한다.
NPM이 제공하는 기본 명령어와 커스텀 명령어 추가방법을 알아보았다.
npm install로 외부 패키지를 다운로드 할 수 있고, 버전을 관리하는 방식에 대해 살펴 보았다.